
7 min reading time
What is SCORM? A Simple Guide for those new to eLearning

SCORM has become so widely used, it’s often referred to as the default or de facto standard of eLearning. But SCORM’s confusing name and technical nature make it difficult for some eLearning professionals to understand.
Not only do you have to search for a great LMS, you have to decide if you need to create SCORM courses. Understanding “what is SCORM?” is essential for trainers and developers who need to decide what role it should play in their learning programs.
Here are the basics you need to know to answer the questions, what is SCORM? What is a SCORM compliant LMS, and how do I create SCORM content?
What is SCORM?
SCORM is a technical specification for eLearning software products. It standardizes the way in which eLearning courses are created, and how they’re launched.
Learning management systems (LMS) and authoring tools are built with this specification in mind and as a result these tools ‘play well’ with each other. If a particular tool doesn’t tow the line, they’re punished by the isolation caused. In practical terms, you’ll hear the phrase “SCORM courses” used frequently. What does that mean? When creating an eLearning course with an authoring tool that is “SCORM compliant” the output is a Zip Folder.
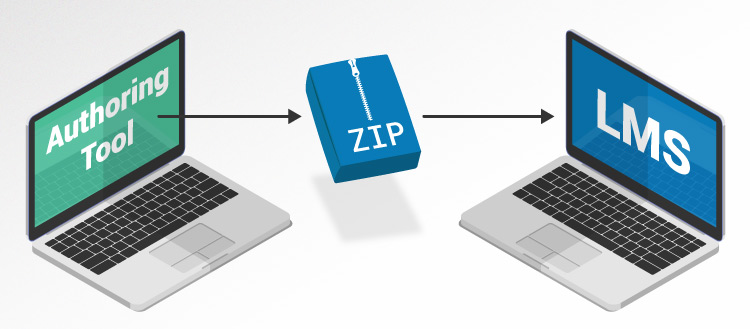
This Zip folder is uploaded to your LMS, and the LMS handles everything from there (so long as it’s SCORM compliant too). When you publish the course, an enrolled learner can launch it in a browser. The LMS collects data to track and report results of their performance. The SCORM course tells the LMS which data to receive.
A Simple Analogy for SCORM
Whenever you have to plug in a device to your computer, you usually use a USB port, right? That’s a standardized specification that all technical hardware makers abide by, so all of your products work with each other easily.

The USB or Universal Serial Bus is a standard that prevents against every device having its own proprietary plug. This helps companies to build products that can exist in an ecosystem. The consumer has more choice too (just don’t mention Apple’s Thunderbolt). It’s the same principle for eLearning.
What does SCORM Mean?
The word SCORM is an acronym and stands for: Shareable Content Object Reference Model. It’s not hard to see why so many people find SCORM confusing! The two parts of the SCORM acronym are actually pretty easy to understand once we separate them out. The SCORM term is made up of two elements that, when combined, answer our question, “what is SCORM?”.
The two main components of ‘SCORM’ are Sharable Content Object and Reference Model.
- Shareable Content Object or SCO: This describes the elements of the SCORM package that can be reused across multiple tools and platforms. Once the various elements of the package are SCORM compliant, the content should be understood by all compatible learning platforms and tools. They are the ‘assets’ used in the course.
- Reference Model: This part of the term tells you that SCORM is a standard, the specification for which can be understood and applied in a consistent way by all who work in the eLearning industry. These are the ‘rules’ everyone follows.
And that’s the heart of SCORM: a set of technical specifications that were developed to provide a common approach to how eLearning content is developed and used.
Since then, SCORM has also gone through a number of iterations. To check if eLearning content, or a tool or system, really is compliant, ask a vendor or developer to explain the details. Is the product compatible with all elements of the SCORM spec, for example? And is it compatible with versions like SCORM 1.2 and SCORM 2004?
What are the benefits of using SCORM?
Now that we understand that SCORM is a means to reduce the chaos in an entire industry – what are the benefits for you? There are actually quite a few, that make up for all the confusion caused:
- It’s a pro-consumer initiative. Courses can be ‘played’ on any compliant LMS, preventing you from being trapped in a poorly performing LMS vendor. As long as you have the zip folders you can simply upload them into alternative LMS if you’re unhappy.
- All high-quality LMSs and Authoring tools are SCORM compliant, this has built a great ecosystem of interoperability and in turn, reliability.
- SCORM’s introduction has reduced the overall cost of delivering training as it doesn’t have to be made bespoke for every system.
- Better quality content. The best course creation tools are compatible with SCORM compliant LMSs.
What does a SCORM course look like?
That’s similar to asking what does a presentation look like! It depends on the content. Most SCORM courses are developed by popular authoring tools and so follow a similar structure. A basic description is that a SCORM course is like a powerpoint presentation with an extra layer of interactivity.
What is tracked by a SCORM course?
When a SCORM course is being taken there are a number of pieces of data being monitored. This data is being tracked and sent back to the LMS. For the version that LearnUpon supports, SCORM 1.2, the data includes:
- lesson_location (where learner left off)
- suspend_data (bookmark with the specific information e.g. paragraph)
- lesson_status (pass, fail, complete, incomplete)
- session_time and total_time
- score_raw (score learner got)
- mastery_score (passing score)
- interactions (individual answers to exam questions, time spent etc.)
These are the status, the suspend data and the mastery score. SCORM generally has four statuses being reported on. These indicate the status of the learner in a particular course.
- incomplete
- completed
- passed
- Failed
Simple right? Not exactly, completion and passing are two different and distinct terms in SCORM. “Complete” means the user completed the module (the smallest unit of eLearning – chapter, pages are other terms used). i.e. they simply completed, there was no exam and nothing to pass… so they are complete.
There’s no point in saying that someone passed a book by reading it, they didn’t have to do an exam, right? That’s a misrepresentation of their status. So, “passed” means that the user not only completed the module but they also passed the module, presumably by doing an exam and acing it! An easy way to remember this is:
- Completed = Completed (no exams)
- Passed = Completed AND Passed (the exam)
- Failed = Completed AND Failed (the exam)
There are two other pieces of data tracked by the LMS from information sent by the SCORM course:
Suspend data: A SCORM course will bookmark the learner’s position in a course. The learner can pick up where they left off if they are interrupted – important for those trying to squeeze training into a busy schedule.
Mastery score: This is SCORM-speak for “passing score”. In other words, the passing score for an exam in the course. Learners must score above or equal to this score in order to pass the module.
Do I need to use SCORM?
Choosing whether or not to use SCORM is usually a balance of two things: the benefits of its use versus the cost (the time and money spent implementing it.) Our CEO Brendan wrote a popular post that goes into detail called To SCORM or not to SCORM. Here’s a digest of the pros and cons to help you choose.
Pros of using SCORM:
- More interactive experience for your learner
- Greater control of the time spent on your courses
- More options to combine course elements and assessments
- Easier migration of your content to a new LMS
Cons of using SCORM:
- The extra expense due to the cost of the authoring tool
- It can be a steep learning curve for new users
- Can be clunky as its an old standard
Bonus consideration: We don’t want to open another layer of complexity so we’ll keep this brief for now. If you do choose to use SCORM, you should actually use xAPI, also known as Tin Can. It’s more modern, less famous and more effective. And producing it is basically the same process! So it’s a win-win.
Are all SCORM compliant LMSs the same?
Not at all. The specification relates to the launch and tracking of the course, with a few stringent rules. SCORM makes sure that certain actions take place and are tracked. Everything else varies LMS to LMS, including the ease of use, interface, and features.
For example, the features LearnUpon has built-in to validate and overcome common SCORM problems. We didn’t have to develop those features to be SCORM compliant, we did so to make the process and experience easier for our users.
Do I need another tool to produce SCORM?
You’ll need another tool to create SCORM content if that’s the way you want to go. There’s an option to build courses with the LMSs own native course builder. If, for example, your need is to deliver internal training that’s compliance-focused, then using a simpler approach may work best. You can build one by uploading the materials you have to hand such as video, powerpoint and other documents, with an exam added on at the end. That content is much easier and less expensive to create. It will not be SCORM compliant though!
If SCORM is a requirement then you’ll need an authoring tool. An authoring tool is a separate piece of software built specifically for its purpose – creating eLearning courses. It’s difficult to choose an authoring tool if you don’t know what you are looking for.
Our advice: Look at the price, the features, the ease of use and the customer support. For a more in-depth look check out our article on the best authoring tools available.
Simplify Your Training Delivery Today
Already have your SCORM courses in order? Uploading them into LearnUpon is quick and easy. The powerful learning management system that has the features and a knowledgeable team you need to achieve training success. Schedule a free demo today!



